How Playtika Achieved AI Automation Customer Service with Apache NiFi – Part 2
By By Roberto Marturano & Florian Simond
By Roberto Marturano & Florian Simond
Part 1 of this article addresses the business logic and results of the request for and implementation of Playtika’s AI-assisted Customer Service (CS) solution.
This solution was developed in-house by Playtika’s team and here they are sharing their experience in developing it and offering tips to those who would like to emulate them.
As stated in the title, the solution was developed using Apache NiFi, commonly referred to as NiFi.
Brief intro to NiFi
Formerly called Niagarafiles, NiFi is a system that automates data flow between systems, a quality that facilitates the automation of repetitive tasks.
Playtika CS agents face numerous repetitive tasks, such as checking players’ metrics, applying pre-determined rules to identify and relay a solution, and many others, abstracting data retrieval and rules implementation into a flow-chart enabled later automation.
After evaluating several solutions, we selected the open-source Apache NiFi tool as the best-suited flow-based programming model that enables visually building the process flow chart representation.
Apache Nifi comes with numerous off-the-shelf generic components (processors), enabling a flow to interact with several third-party tools such as SQL databases, Kafka, REST services, and more. Fault-tolerant, it is designed to work with streams of data and can easily be extended with custom blocks.
CS Automation Tool assisting CS agents
The CS Automation Tool is not designed to replace agents but to provide each of them with an automated personal assistant. It performs tedious and time-consuming grunt work such as consulting multiple data sources, analyzing the player’s history, copy-pasting template canned answers, etc.
Armed with that information, the CS Agent receives in-depth insights about the player and can focus on providing stellar answers to the player instead of struggling to meet time-to-resolution imperatives.
The diagram in Figure 1 shows the Flow Automation Service system architecture.
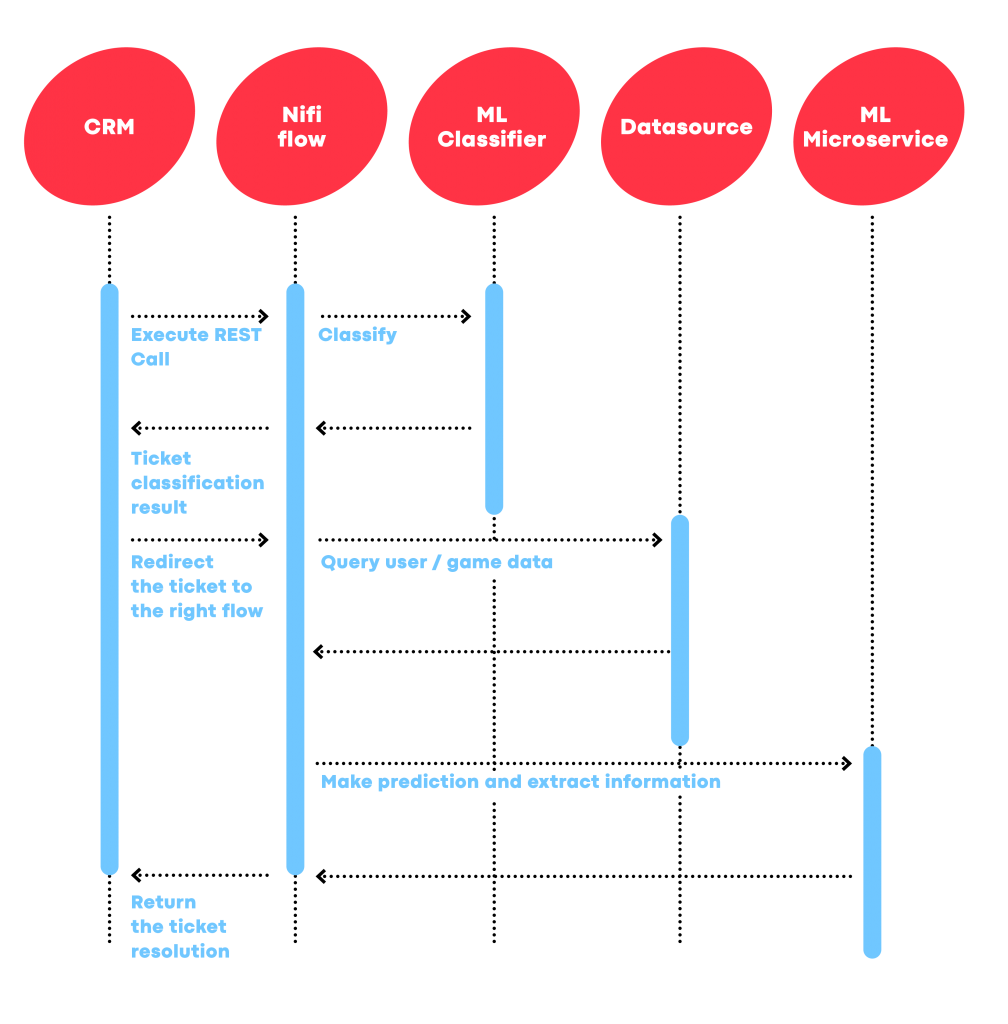
The CRM triggers the pipeline’s flow by sending an incoming ticket to the CS Automation Tool through a REST call:
- the ticket is first classified (through an ML microservice),
- the classified ticket is rerouted to the CRM,
- based on the predicted category, the ticket is redirected to the appropriate NiFi flow,
- within this flow, external data sources / ML endpoints are invoked to provide a deeper understanding of the tickets’ context and formulate resolutions based on the acquired understanding,
- the ticket is returned to the CRM with attached relevant data and suggested answers.
The resolutions, formulated by flows built on NiFi, to the tickets are provided back to CRM as responses. Agents act as a final gatekeeper who evaluates the CS Automation Tool’s resolutions, refine them, and finally reply to the user.
Flow design
The flow starts with a REST HTTP endpoint: it receives the incoming message (FlowFile) propagated to the following steps. The FlowFile is manipulated and enriched throughout the flow, and, eventually, the response is sent to the application.
The intermediate stages aim to recreate context around users’ requests, e.g., current in-game activities, purchases, information regarding previously sent tickets, or others. This enriched knowledge, added to the users’ ticket descriptions, is leveraged to suggest ticket resolutions to the CS agents. Subsequently, CS agents are given options to apply, customize or discard the proposed resolutions.
Let’s take, for example, the scenario depicted in Figure 2: a player sends a help request stating that he cannot see his last purchase listed in his account.
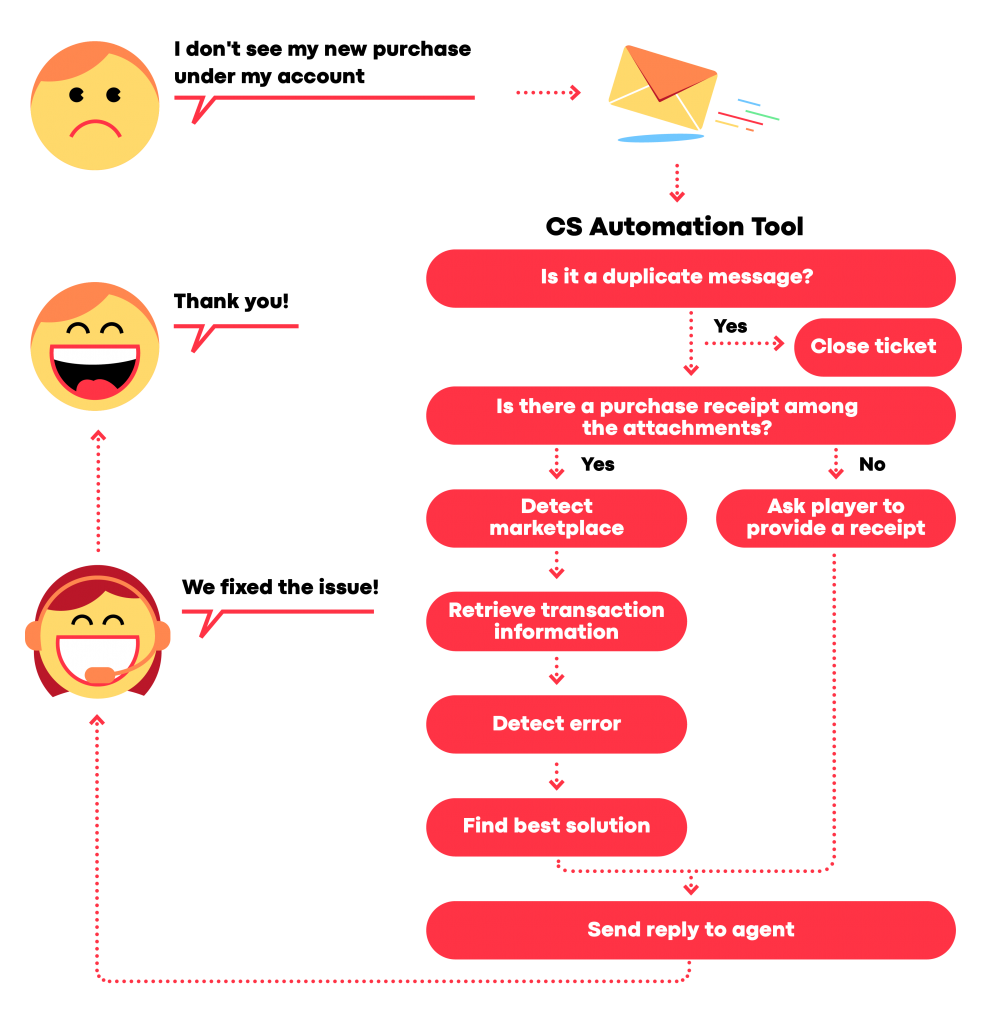
Before the CS agent sees the ticket, CRM forwards it to the NiFi flow that computes the relevant pre-determined checks. It:
- verifies if the ticket is a duplicate
- if yes, it closes the ticket
- if no, it continues to the next step
- checks if the user attached a purchase receipt
- if yes it:
- identifies the marketplace where the purchase was made
- retrieves the transaction information
- identifies the error
- suggests a solution
- if no, it asks the player to provide the receipt
- if yes it:
This means the CS agents never waste time dismissing duplicate queries or exchanging emails with the user to obtain missing documentation, nor checking data relative to the documentation provided.
By the time queries requiring human attention reach his screen, the CS Automation Tool presents the agent with a suggested solution and a template answer.
All the CS agent has to do is approve or edit the suggested answer, leaving him time to personalize it if relevant all in record time, thus enhancing the user’s satisfaction.
Technical Specifications and Instructions
Instead of executing flows on a standalone server, we opted to configure the elected Apache NiFi cluster on K8s so as to benefit from Kubernetes’ scalability and fault tolerance.
Unfortunately, there was no available standard procedure to set up NiFi on K8s, so we had to create one.
Here is the step-by-step instruction from creating a namespace in K8s, installing the Helm package manager, and the standard coordination service Zookeeper. We also added tips to increase the NiFi fault tolerance on K8s by storing it on a persistent volume, with the aim to run NiFi flow with K8s when in production.
Installation instructions
Prerequisite:
- Kubernetes
- Helm v2.12.0
- Zookeeper
To set up NiFi:
- Create a custom Namespace
kubectl create -f namespace.yaml
with the following namespace.yaml content:apiVersion: v1
kind: Namespace
metadata:
labels:
name: nifi
name: nifi - Create a custom Context
Edit the~/.kube/configfile and add the following:...
- context:
cluster: your_k8s_cluster
namespace: nifi
user: your_user
name: nifi
... - Install Helm (version v2.12.0): Package manager
To set up Zookeeper
To install Zookeeper chart (Bitnami’s Helm package)
- Clone Zookeeper’s chart:
git clone https://github.com/bitnami/charts.git
cd charts/bitnami/zookeeper - Edit values.yaml and set
replicaCount: 1, in order to let NiFi clustering correctly - Install Zookeeper via Helm:
helm install -f values.yaml --name zookeeper . --kube-context nifi --namespace nifi - In the command output you should see the service FQDN:
zookeeper.nifi.your_k8s_cluster.local
Creating Persistent Volumes on Kubernetes
To ensure NiFi flows’ persistence across time, we need to store them in a Persistent Volume (PV).
This requires enabling NiFi read/write privileges on a shared storage space and creating a PV for each Kubernetes pod. Then, mount HDFS directories on each PV with NFS (Network File System).
Allocate dedicated PVs under a unique Storage ClassName created for that purpose, which restricts access to the PV to the deployed NiFi cluster.
Configuring NiFi
- Ensure Zookeeper is up and running on Kubernetes
- Clone Helm chart:
git clone https://github.com/cetic/helm-nifi - Edit the following configuration files:
- configs/zookeeper.properties : assign to
server.1the Zookeeper FQDN - set the following Values.yaml
- set the replica count (e.g., 3)
- set the following Templates/statefulset.yml:
volumeClaimTemplates: specify the Storage Class Name defined in the previous step and bind all needed volumeMounts. In this way, each NiFi pod will mount some path on top of HDFS.
- configs/zookeeper.properties : assign to
- Install NiFi via Helm:
helm install -f values.yaml --name nifi . --kube-context nifi-dev --namespace nifi --debug - This generates a report similar to the one displayed in Figure 3.
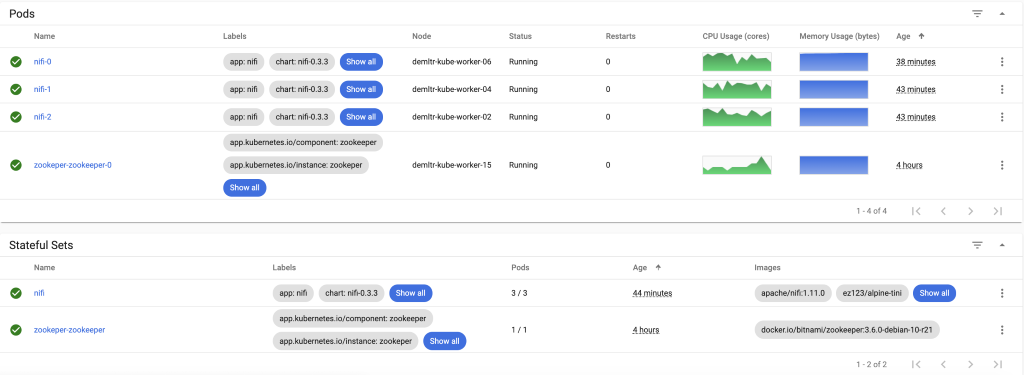
Making NiFi flow with persistent volume
The above instructions enable you to install and set up a NiFi cluster with one main pod and two supporting ones. Although this setting is designed to handle potential faults, we preferred increasing the fault-tolerance settings by having a backup NiFi flow. That NiFi flow contains custom NiFi components/processors, loaded from the additional pod in case all three original pods die.
We opted to store the NiFi flows in pod-specific persistent volumes from which K8s can load NiFi flows with pods as, without persistence, the default disk space is ephemeral. Having a persistent volume allows custom NiFi components/processors to be loaded upon pod restarts.
This is the configuration process:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nifi-pv-0
spec:
storageClassName: nifi-storage
capacity:
storage: 50Gi
volumeMode: Filesystem
persistentVolumeReclaimPolicy: Retain
nfs:
server: your_remote_nfs_server
path: /path/to/nifi-0 # becomes nifi-1, nifi-2, etc.
accessModes:
- ReadWriteOnce
With the above procedure, we are now able to run NiFi flows on K8s in production, which is able to load custom NiFi flows even in cases of pod restarts.
We hoped this was useful for you and can help you in developing NiFi based AI-assisted solutions for your own purposes.






