Dynamic Pipelines for ML
By Nitai Itzhacky
Introduction
The field of AI has been rapidly expanding over the past few years, with machine learning (ML) algorithms typically at the core of many AI solutions. The proliferation of machine learning models presents new challenges related to scale, efficiency and automation. The development of the ML lifecycle involves numerous components, including data processing, model training, model deployment, model monitoring and more. ML pipelines serve as the foundation of the ML lifecycle, encompassing a series of interconnected steps that facilitate the flow and orchestration between them. These pipelines automate machine learning workflows, ranging from scalable ML experiments to inference pipelines.
As the number of machine learning models continues to grow, the need for more adaptable and efficient solutions becomes increasingly crucial. Managing numerous models manually can significantly increase the coupling between different pipelines and components of the project, as well as inflate the total amount of code, making it less readable and more challenging to maintain. This is where the concept of dynamic pipelines proves to be invaluable. Dynamic pipelines offer a versatile approach to managing and scaling a wide array of models, providing a flexible framework that dynamically adjusts to varying workloads and changing requirements.
In this article, we explore the significance of dynamic pipelines in addressing the challenges posed by the ever-increasing influx of machine learning models. We delve into the practical implementation of dynamic pipelines using popular workflow management tools such as Airflow and ZenML, providing valuable insights into how organizations can effectively create and manage these adaptive pipelines for seamless ML lifecycle management.
Airflow Dynamic DAGs
Airflow stands as one of the most popular open-source platforms for orchestrating workflows and automating data pipelines. Moreover, Airflow finds utility in ML pipelines. It enables the scheduling and monitoring of ML experiments, along with the creation of batch inference pipelines for production purposes.
A closer examination of a typical Airflow Directed Acyclic Graph (DAG) is warranted. Imagine an inference pipeline for a regression model.
with DAG('inference_pipeline', default_args=default_args, schedule_interval='@daily') as dag:
compute_features = FeatureSetOperator(
task_id='compute_features',
sql=features_sql_query,
features_table=features_table,
dag=dag
)
predict_regression = InferenceOperator(
task_id="predict_regression",
model=regression_model,
features_table=features_table,
prediction_table=prediction_table,
dag=dag
)
export_data = TableToKafkaOperator(
task_id="export_data",
source_table=prediction_table,
destination_topic="regression_predictions",
kafka_details=kafka_details,
dag=dag
)
compute_features >> predict_regression >> export_data
The provided code establishes a simple inference pipeline with an Airflow DAG. The pipeline accomplishes several tasks: computation of a feature set, generation of predictions stored in the predictions table, and eventual exportation of data to Kafka. The implantation of these tasks is encapsulated in reusable custom Airflow operators. The resulting DAG, generated by this code, is depicted in the subsequent figure:

Now, let’s delve into the scenario where numerous models predict distinct labels using the same feature set. Airflow offers the ability to dynamically construct the sequence of DAG tasks, thereby allowing the construction based on the models’ configurations. This proves notably more convenient than explicitly creating tasks for each model in separate code lines, particularly when these configurations are employed in other DAGs, such as training or monitoring processes.
with DAG('dynamic_inference_pipeline', default_args=default_args, schedule_interval='@daily') as dynamic_dag:
compute_features = FeatureSetOperator(
task_id='compute_features',
sql=features_sql_query,
features_table=features_table,
dag=dynamic_dag
)
export_data = TableToKafkaOperator(
task_id="export_data",
source_table=prediction_table,
destination_topic="regression_predictions",
kafka_details=kafka_details,
dag=dynamic_dag
)
for regression_model in regression_models:
predict_regression = InferenceOperator(
task_id=f"predict_{regression_model.name}",
model=regression_model,
features_table=features_table,
prediction_table=prediction_table,
dag=dynamic_dag
)
compute_features >> predict_regression >> export_data
In the provided code snippet, an iteration traverses a list of models, generating inference tasks for each model. The simple act of adding models to this list seamlessly adjusts the DAG structure accordingly. In this instance, every inference task contributes a prediction entry to the predictions table, including both the prediction value and the label name. Ultimately, all predictions find their way to a common Kafka topic. This dynamic capability streamlines the management of multiple models while minimizing the amount of custom code.
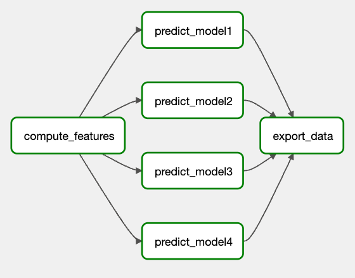
Taking the dynamic capabilities to a more advanced level, consider the need to replicate this pipeline for multiple mobile games. Ideally, designing a distinct DAG for each game ensures redundancy. Airflow’s versatility extends to the dynamic creation of DAGs as well. Here, the newly introduced @dag decorator in Airflow 2 proves particularly convenient. (For those employing Airflow 1, defining a dynamic DAG is still feasible, albeit slightly less elegant).
game_confs = {
"game1": GameConf(features_query=slotomania_feature_query, regression_models=models_game1),
"game2": GameConf(features_query=slotomania_feature_query, regression_models=models_game2),
}
for game_name, game_conf in game_confs.items():
game_features_table = f"{features_table}_{game_name}"
game_prediction_table = f"{prediction_table}_{game_name}"
game_kafka_topic = f"regression_predictions_{game_name}"
@dag(dag_id=f"{game_name}_inference_pipeline", default_args=default_args, schedule_interval='@daily')
def inference_dag():
compute_features = FeatureSetOperator(
task_id='compute_features',
sql=game_conf.features_query,
features_table=game_features_table
)
export_data = TableToKafkaOperator(
task_id="export_data",
source_table=game_prediction_table,
destination_topic=game_kafka_topic,
kafka_details=kafka_details
)
for regression_model in game_conf.regression_models:
predict_regression = InferenceOperator(
task_id=f"predict_{regression_model.name}",
model=regression_model,
features_table=game_features_table,
prediction_table=game_prediction_table
)
compute_features >> predict_regression >> export_data
inference_dag()
For each mobile game, we configure the relevant models and allocate the necessary resources. Subsequently, we iterate over each game, creating a DAG using the same template based on its pertinent configuration. Instead of generating multiple DAGs that perform similar functions, it’s imperative to define the DAG only once. Incorporating each new game into our configurations will trigger the creation of an appropriate inference pipeline.
ZenML
ZenML stands as an innovative and robust framework designed to streamline and optimize the machine learning workflow. It furnishes a comprehensive end-to-end solution tailored for data scientists and ML engineers. This open-source MLOps framework decouples infrastructure from code, employing a user-friendly Pythonic SDK. This approach empowers data scientists and ML engineers to devise ML workflows employing their preferred tools, experiment locally, and seamlessly transition to a production environment. Furthermore, this decoupling facilitates the migration between various orchestration platforms, such as Airflow and Kubeflow pipelines, without necessitating any alterations to the code.
Initiating your journey with ZenML is particularly straightforward, in contrast to Airflow. To begin your exploration of ZenML, you can install the ZenML package.
pip install zenmlOnce the package is installed, you can compose ZenML code and execute it locally with no additional effort.
ZenML Concepts
ZenML centers around pipelines and steps as its foundational building blocks, whereas Airflow introduces the concept of DAGs and tasks. Nevertheless, both tools employ simple method
decorators to define these building blocks. Using Airflow, we demonstrated the ease of crafting dynamic inference pipeline. Now, let’s turn our attention to ZenML and explore its applicability in ML experimentation scenarios.
@step
def get_iris_dataframe() -> Tuple[Annotated[pd.DataFrame, "features"], Annotated[pd.Series, "labels"]]:
iris = datasets.load_iris()
return pd.DataFrame(iris.data, columns=iris.feature_names), pd.Series(iris.target, name='label')
@step
def explor_data(X: pd.DataFrame, y: pd.Series):
print(f'Feature columns: {", ".join(X.columns)}')
print(f'Number of samples: {len(X)}')
print('Correlation between the features and the label:')
print(X.corrwith(y))
@pipeline
def explor_iris_data():
features, labels = get_iris_dataframe()
explor_data(features, labels)
if __name__ == '__main__':
explor_iris_data()
In this example, we construct a pipeline that delves into iris data sourced from scikit-learn. It comprises of 2 steps: one data loading and the other for data exploration. ZenML can also generate a dashboard to visually represent the pipelines it defines. To learn how to utilize the dashboard locally, refer to https://github.com/zenml-io/zenml-dashboard. Following the setup of a local dashboard and the execution of the pipeline, the dashboard will present an illustration of the pipeline run, as depicted below.
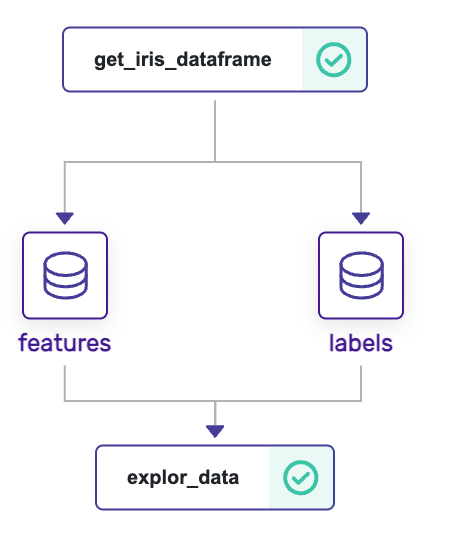
The creation and local execution of such pipelines are straightforward. Data scientists can dive right into their work immediately after integrating the ZenML package into their environment. When it comes to deploying this pipeline to a production setting, no alterations to the code are required. Frequently, data scientists write code that doesn’t seamlessly integrate into a production re-training mechanism or an inference pipeline. By leveraging ZenML, simple experiments that are executed locally can be effortlessly scaled up into comprehensive production pipelines.
Hyperparameter Tuning with Dynamic Pipelines in ZenML
ZenML also provides the capability to generate pipelines dynamically. To illustrate this, let’s delve into a practical training pipeline example. Hyperparameter tuning holds immense significance in machine learning experimentation. This process is aimed at identifying the optimal combination of hyperparameters for a given model, a factor that can profoundly influence its performance and generalization. By systematically exploring diverse hyperparameter settings and assessing their impact on the model’s performance, we can fine-tune the model to attain enhanced results. Various tuning search strategies exist, rendering it challenging to precisely define the steps of a training pipeline during the pipeline’s developmental stage. Thus, the ability to dynamically create steps based on the logic of the search algorithm proves to be exceedingly valuable. Although ZenML does not yet provide out-of-the-box support for hyperparameter tuning, its implementation is straightforward, and it is poised to become even more streamlined in future versions. For this example, let’s adopt the straightforward grid search approach for hyperparameter tuning of a random forest model.
estimators = range(100, 500, 100)
max_depths = range(1, 3)
criterions = ['gini', 'log_loss']
hyperparameter_configs = [{
'n_estimators': estimator,
'max_depth': max_depth,
'criterion': criterion
} for
estimator,
max_depth,
criterion in itertools.product(estimators,
max_depths,
criterions)]
Having accumulated the hyperparameter configurations within a variable, we proceed to generate the training pipeline’s steps based on these configurations.The following code snippet generates a pipeline for hyperparameter tuning, which dynamically creates a training step for each hyperparameter configuration.
@pipeline
def hyperparameter_tuning(configs):
features, labels = get_iris_data()
X_train, X_test, y_train, y_test = split_data(features, labels)
for i, config in enumerate(configs):
y_pred = train_and_predict_rf_classifier(X_train,
y_train,
X_test,
random_forest_config=config)
print_value(y_pred)
if __name__ == '__main__':
estimators = range(100, 500, 100)
max_depths = range(1, 3)
criterions = ['gini', 'log_loss']
hyperparameter_configs = [{
'n_estimators': estimator,
'max_depth': max_depth,
'criterion': criterion
} for
estimator,
max_depth,
criterion in itertools.product(estimators,
max_depths,
criterions)]
hyperparameter_tuning(hyperparameter_configs)
For the comprehensive implementation of all steps, please refer to the GitHub repository: https://github.com/nitay93/zenml-playground.
Moving forward, our focus shifts to the evaluation and comparison of the distinct models. We will introduce a step for each hyperparameter configuration, responsible for assessing its performance score. These individual scores will then be collated into a solitary step entrusted with comparing the evaluations and determining the optimal hyperparameter configuration.
@pipeline
def hyperparameter_tuning(configs):
features, labels = get_iris_data()
X_train , X_test, y_train, y_test = split_data(features, labels)
evaluation_steps = []
for i, config in enumerate(configs):
y_pred = train_and_predict_rf_classifier(X_train,
y_train,
X_test,
random_forest_config=config)
evaluation_step_id = f"evaluation_{i+1}"
calc_accuracy(model_parameters=config,
y_test=y_test,
y_pred=y_pred,
id=evaluation_step_id)
evaluation_steps.append(evaluation_step_id)
compare_score(evaluation_steps=evaluation_steps, after=evaluation_steps)
Within this pipeline, the calc_accuracy function will yield an object encompassing the tested model parameters alongside their corresponding accuracy scores. Presently, ZenML lacks support for creating steps capable of receiving an unknown number of inputs. To circumvent this, we will initially validate that all evaluation steps conclude before the commencement of the compare_score step. Each ZenML step can receive a parameter named “after,” assigned a list of step IDs to ensure the step awaits the completion of specified predecessors. Furthermore, the compare_score step requires access to the output values from the evaluation steps. We accomplish this by conveying the evaluation step IDs to compare_score and subsequently extracting the output values through their respective IDs. This process is implemented within the collect_step_output method shown below.
def collect_step_outputs(id_list: List[str] = None):
"""
Collect the step outputs that correspond to the id_list
"""
run_name = get_step_context().pipeline_run.name
run = Client().get_pipeline_run(run_name)
return {step_name: step.outputs["output"].load() for step_name, step in run.steps.items() if step_name in id_list}
@step
def compare_score(evaluation_steps: List[str], is_max=True) -> dict:
"""Compare scores over multiple evaluation outputs."""
evaluation_results = collect_step_outputs(evaluation_steps)
optimize = max if is_max else min
optimal_result = optimize(evaluation_results.values(), key=lambda x: x.score)
print(
f"optimal evaluation at {optimal_result.model_parameters}. score = "
f"{optimal_result.score*100:.2f}%"
)
return optimal_result.model_parameters
We have successfully crafted a pipeline that compares models trained with varying hyperparameters. Nonetheless, the accuracy of this model may be skewed due to its alignment with the specific dataset used for training. To obtain a more realistic outcome and mitigate overfitting, we employ the train-validation-test approach. First, a test set is reserved from the dataset exclusively for the purpose of unbiased evaluation. Second, the remaining data is partitioned into a training set and a validation set. The models are trained on the training set and their accuracy scores are determined based on the validation set. Subsequently, the model demonstrating the best performance is retrained on the entire training-validation set. The final model’s performance is then assessed using the test set that was kept aside.
@pipeline
def hyperparameter_tuning(configs):
X, y = get_iris_data_arrays()
X_train_val, X_test, y_train_val, y_test = split_data(X, y)
evaluation_steps = []
for i, config in enumerate(configs):
X_train, X_val, y_train, y_val = split_data(X_train_val, y_train_val)
y_pred = train_and_predict_rf_classifier(X_train,
y_train,
X_val,
random_forest_config=config)
evaluation_step_id = f"evaluation_{i + 1}"
calc_accuracy(model_parameters=config,
y_test=y_val,
y_pred=y_pred,
id=evaluation_step_id)
evaluation_steps.append(evaluation_step_id)
best_hyperparameter_config = compare_score(evaluation_steps=evaluation_steps, after=evaluation_steps)
y_pred = train_and_predict_rf_classifier(
X_train_val,
y_train_val,
X_test,
random_forest_config=best_hyperparameter_config)
calc_accuracy(model_parameters=best_hyperparameter_config,
y_test=y_test,
y_pred=y_pred,
final_performance=True)
This dynamic hyperparameter tuning pipeline template can be readily adapted for diverse experiments by adjusting the hyperparameter configurations. The versatility can be further expanded by configuring the data loading step, training step, or evaluation steps as pipeline variables. This accommodates different datasets, various model types, and distinct evaluation metrics. This approach allows for the effortless creation of numerous experiments using a standardized pipeline template, creating a hyperparameter tuning engine that curtails code redundancy and promotes uniformity in experiment generation across the ML ecosystem within your organization.
Conclusion
Dynamic pipelines hold valuable applications throughout the ML lifecycle. They contribute to the generalization of various ML workflows, mitigating development complexities by controlling pipeline generation with minimal code alterations. In particular, they adeptly manage the scalability of models trained or employed in a pipeline. Additionally, they facilitate the creation of generic pipeline templates that cater to different use cases, all while adhering to the same underlying logic.
Pipeline orchestration tools like Airflow and ZenML empower data scientists and machine learning engineers to effortlessly construct dynamic pipelines, leveraging an intuitive approach. As the demand for AI solutions continues to surge, dynamic pipelines emerge as a pivotal solution, enhancing scalability and modularity. This, in turn, accelerates time-to-market while elevating the quality of your ML workflows.