Modern Security Regression Testing
By Itamar Weller
In the ever-evolving landscape of cybersecurity, identifying and addressing vulnerabilities is a critical task for product security teams. Among the stages of a vulnerability’s life cycle, regression testing plays a vital role in ensuring those pesky vulnerabilities do not resurface. However, traditional manual regression testing methods have their limitations. In this blog post, we will explore a new approach that scales the regression testing stage, resulting in an innovative process fit for today’s world.
As security personnel, you’ve likely encountered this all-too-familiar scenario: A vulnerability lands on your desk, be it from a concerned user, bug bounty, penetration test, etc. You promptly engage with the developer, who diligently patches the issue. Problem solved, right? But wait! Fast forward a few weeks or months, and there it is again, that same pesky vulnerability rearing its head. You approach the developer, only to hear them nonchalantly say, “Oops! We made a configuration change and inadvertently rolled back the patch.” Ah, the classic case of regression. And that’s precisely why regression testing takes center stage in the thrilling life cycle of vulnerabilities.
In the past, regression testing was primarily done manually, which presented several challenges. Security engineers had to painstakingly retest each vulnerability fix, potentially leading to human errors and inefficiencies. Moreover, the process lacked scalability, making it difficult to keep up with the growing number of vulnerabilities and fixes, and, perhaps most importantly, the huge waste of the team’s time. In our case, we managed a queue of Jira tickets that required a retest using a special label. This was a never-ending task that prevented our team from scaling. These limitations called for an innovative approach to address these issues and streamline the regression testing process.
To overcome the limitations of traditional regression testing, our product security team devised a new approach that incorporates automation and scale. The first step involves identifying vulnerabilities that qualify for automated regression testing. These vulnerabilities should meet the following criteria:
- Can the vulnerability be simply reproduced? i.e., one simple request, and expect a unique value in the response.
- Can the vulnerability be reproduced by using automation?
Here are a few examples that meet the above criteria:
- Leaked credentials in response body
- API calls without session validation
Doing it right
The process looks like this:
- Once a vulnerability is discovered, our security engineers decide if it is suitable for an automated regression test as part of the triage phase.
If it does, they tag it with a dedicated Jira label and create a custom Nuclei template specifically designed to check for the regression of the specific vulnerability.
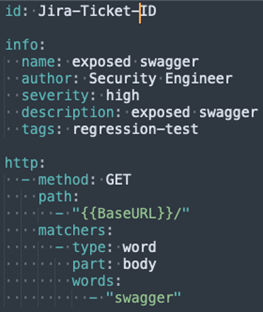
For example:
Vulnerability: A service exposed a swagger file to the world
Template:

- They then create a pull request with the new custom template in our automated regression tests code repository.
- An automated job is scheduled to run periodically, pulling updates from the repository and executing the automated regression tests’ templates.
- If a regression test fails, the vulnerability’s Jira ticket is automatically reopened (using Jtrack, an open source program created by our team).
The structure of the repository is a folder for each regression test, which includes the custom template and a target file with the vulnerable endpoints’ URLs. This makes it natively integrated to Nuclei as a source for templates. In addition, the ID of the custom template matches the Jira ticket associated with the vulnerability, making it possible for the automated job to reopen the ticket.
Final Thoughts: Wrapping It All Up
This new approach to vulnerability regression testing offers several advantages over manual methods. First, it significantly improves efficiency by automating the testing process, eliminating the need for security personnel’s human touch. This saves valuable time and allows security engineers to focus on more complex security tasks. Additionally, the automated nature of the process makes the regression continuous and not a point in time test.
Effective regression testing should be a part of every company’s vulnerability life cycle. By adopting an automated approach to regression testing, our product security team has been able to enhance the efficiency and accuracy of the vulnerability life cycle and, even more importantly, save valuable time! We encourage other companies and security professionals to consider implementing similar methodologies to bring their security maturity one step forward.






