Agile Penetration Testing
By Rotem Reiss
Keeping security up to speed with Agile development is a challenging task, especially when you are responsible for the product security of a mobile gaming company and monetization platform that has over 34 million monthly active users, across a portfolio of game titles.
In this blog post, we are sharing how our product security team evolved from adhering to a traditional penetration testing approach to one that is more Agile and focused on feature-driven penetration testing.
Our journey started approximately two years ago, with a portfolio of over 14 games, hundreds of micro-services, dozens of internal production-supporting applications, code pushed to production multiple times a day and an R&D group of around 1,500 people. Despite the cheetah-fast product development, our product security quality assurance generally focused on annual penetration tests to evaluate of our products’ security maturity.
As you can imagine, defining the scope of such penetration tests is extremely hard and ineffective. New features are constantly released, and therefore may not be included in the annual penetration test. The bad guys, however, will not wait for us to test the new features.
It became clear that we had to shift to Agile penetration testing, ASAP. We did so by first answering a few questions and defining our main constraints:
- How and when should we know about new features?
- How can we identify risky changes in real-time?
- How can we shift left and test features as early as possible, while keeping the business running at the same velocity as before?
- How can we cover a wider attack surface with the same means (budget and personnel)?
Let’s take a deep dive into how we answered these questions.
As you can assume, we wanted to know about new features, while they were still in the concept or early design phases. To achieve this goal, we established connections with two channels:
- Architects
We made sure to train all our software architects (who we consider to be security architects by default) to perform threat modeling, as part of their high-level designs, for every new feature, we also had them get a second opinion from us on any high-risk features. This made it possible for us to be kept in the loop, on most cases.
[Enrichment fact] Our threat modeling process contains three parts:- A few basic questions to assess the feature’s risk level – whether they need a “second opinion” from our application security experts.
- Composing what we call “abuser-stories,” the same as user-stories you might know from the Agile methodology, but as an “abuser.”
For example:
“As a player, I want to spin the wheel once and collect a reward.” Possible abuser-stories out of this user-story include:
“As an abuser, I want to control the reward amount”.
“As an abuser, I want to spin the wheel more than once, to collect multiple rewards”. - Mapping the assets, threats, and actors with S.T.R.I.D.E and describing the security controls we’d like to add.
- Steering committee with the various business-units
Once every six weeks, we meet with every business unit’s stakeholders to discuss the security maturity of said business units. We go over items, such as their open security vulnerabilities, infrastructure security (WAF, servers hardening), new features being worked on, and how to define action-items to improve their overall security-maturity scores.
That allows us to stay up to date on new features, infrastructure changes, managerial changes, and roadmaps, while constantly endeavoring to improve their security maturity score.
Stay tuned for an all-new blog post about our scoring system and KPI measurement.
Although the above channels give us incredible visibility into new features and reduces the risk of design bugs, we still had to find a way to focus our penetration tests on other ad-hoc risky changes, like possible injections, newly exposed API endpoints etc.
While some traditional scanners (SA/DA/IAST) might help with that, we believe that those are too noisy, and might paralyze a small application security team. Therefore, we tried a new approach using a platform (provided to us by a cyber-security vendor) that allows us to detect high-risk changes, by defining rules and actions when those changes are triggered.
The high-risk changes could be defined by various levels: commit level, code repository level or on a “product”/”application” level.
Once we were aware of new features and risky changes, we could define the actions we needed to take. These actions were – and still are – mostly what we call “security challenges;” tasks for our penetration testers to try and “break” the risky functionality.
The challenges are performed as early as possible, but usually aren’t classified as release blockers.
Here are some examples of what triggers a security challenge:
- High-level-design of a high-risk feature (manual):
Mostly features that involve PII (Personal Identifiable Information), game economy changes, or other sensitive functionality changes (authentication/authorization flows). - Automated workflows from our risk management platform:
A new API route is publicly exposed, and- Has user inputs that are not properly validated.
- Interacts with payment data or PII.
Now, for my favorite part. How can we cover a wider attack surface with the same means? Is this even possible?
It is!
Once we could focus our penetration tests on risky changes, rather than on a wide, amorphous scope, we could also shift some of our penetration testing budget to other activities, such as bug-bounty programs.
We started by launching an internal bug-bounty program for employees only, and the program’s results surprisingly revealed multiple critical and high severity bugs.
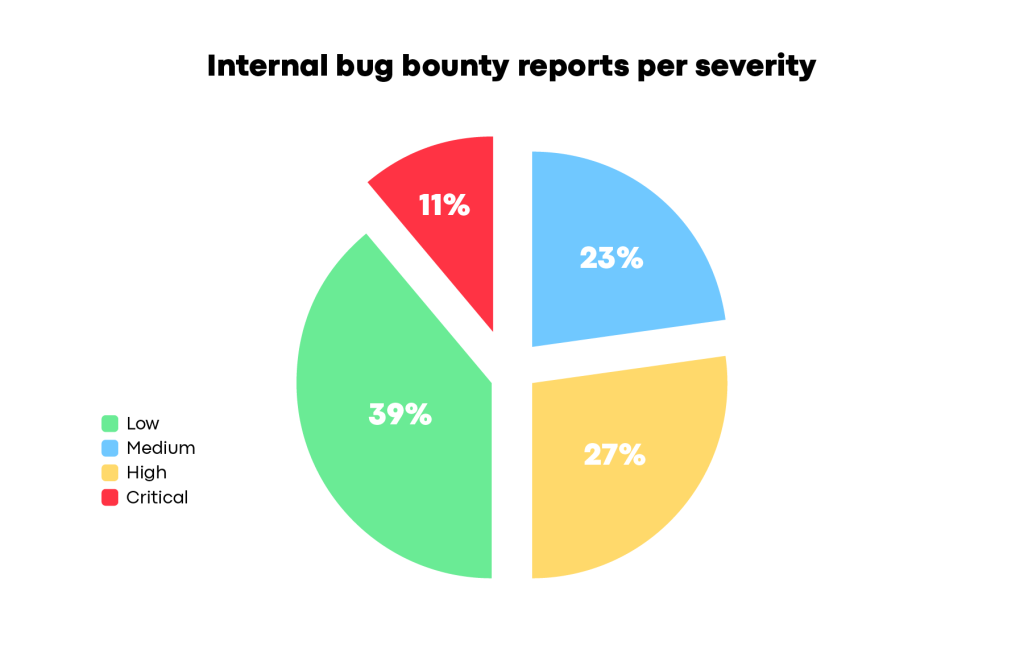
Stay tuned to hear more about our internal bug bounty program, in a dedicated blog post.
A few months after launching the internal bug bounty program, we also launched an external private program. With both programs up and running, we were able to reveal many more bugs, without increasing our penetration testing budget.
Tell me where it hurts
Although it might sound sublime, the road to this final result was a little bumpy, and we believe that learning from those mistakes is just as important as achieving the result we sought.
First, it took us a few months to be able to fine-tune our automated rules and get enough information on new features, for us to even create the challenges. This forced us to integrate traditional penetration testing with the more Agile, features-driven penetration testing, until we were able to hit the ground running.
While we still have not reached our coveted sweet spot, we’ve made huge progress and are headed in the right direction.
Once we finally gathered a decent list of “security challenges,” we had a new challenge, which is partly specific to the gaming industry: ensuring our penetration testers know the UI flow that consumes the suspected API, especially when some of the features are only available to specific player segments (e.g., level X and above, specific countries, etc.).
We sought to overcome this obstacle by opening a communication channel between our penetration testers and our QA leads. This channel was designed to enable them to add the UI steps and provide us with the proper user accounts for our tests.
We are still seeking the proper balance between feature-driven penetration tests and regression penetration tests. However, we believe that our bug-bounty programs, and other security assessments create a satisfactory balance.
Summary
To summarize all the above, we believe that an organization and its product security team should aim for a holistic application security program, that:
- Relies on multiple types of assessment and embracing crowdsourcing, wherever possible.
- Integrates well with the rest of its R&D group and moves at a similar velocity.
- Shifts the common practice that penetration testing is done on the right side of the SDLC and looks at the risks from both the outside-in (the right side of the SDLC) and the inside-out (the left side of the SDLC).






