Event Processing in Playtika Data Platform: Part II – Design Overview
By Oleg Yermilov
Welcome back to our series on event data management at Playtika! In our previous article, we discussed the role and importance of Playtika’s data ingestion framework, known as CEFI (Centralized Event Formatting and Ingestion). This framework is crucial for unlocking the full potential of event data for game studios. We explored, at a high level, how CEFI overcomes common obstacles in delivering event data for a variety of use cases, including analytics, AI, and operations. Now, it’s time to delve deeper into CEFI’s components and understand how it offers a comprehensive range of event ingestion and processing functionalities through self-service, automation, governance, and data quality.
In this article, we will examine the various aspects of event ingestion. We will discuss the essential features required for successful event processing. By grasping how event ingestion operates and its inherent challenges, you’ll gain insights into designing a robust event ingestion and processing solution that maximizes the benefits of your event data.
This post paves the way for subsequent articles that will provide a more thorough exploration of every aspect within the event ingestion problem domain.
Event Ingestion Building Blocks
Event ingestion solutions, such as the CEFI framework, consist of several crucial components vital for efficient data processing and analysis. These fundamental components are:
- Event Consumption from Message Broker: Central to our ingestion process is the ability to consume events from a Kafka topic. This foundational step ensures that the incoming event is captured from the source and is prepared for subsequent processing.
- Event Mirroring: This component handles the online, real-time replication of event data across various Kafka clusters. It proves beneficial in a variety of use – from infrastructural separation between operations and data realms to data locality, event data backup, and recovery.
- Event Routing: During the initial phase of the event data flow, the routing component guides events in their original format to suitable destinations for further processing. Such routing optimizes the performance of event processing by ensuring each event type follows its specific processing path. Efficient event routing mitigates performance bottlenecks and ensures prompt processing, allowing the platform to scale effectively.
- Event Filtering: Filtering acts as a gatekeeper that only permits relevant events to advance. Through filters, the system can scan the incoming stream, retaining data that meets specific criteria while discarding non-essential information. This process enhances data quality and reduces unnecessary processing overhead, promoting efficient resource use. Event filtering can be categorized into two types: basic stateless filtering and advanced stateful filtering or filtering based on event semantics.
- Event Transformation: This involves converting raw event data into a structured format suitable for various analytical, operational, and AI tasks. Activities include flattening intricate JSON structures, systematizing nested data, and improving the overall data quality. The aim is to ensure data accuracy and prepare it for insightful utilization.
- Event Enrichment: Enrichment augments raw data with added context or details. This can include geolocation data, customer characteristics, or any other relevant insights that deepen the analysis. Event enrichment equips analysts with richer datasets for more insightful interpretations, leading to more informed decision-making.
- Event Validation: This process ensures the data’s integrity and overall quality. Events undergo scrutiny to verify their alignment with predefined standards and specific rules, minimizing the risk of erroneous or corrupted data affecting downstream processes. Validation safeguards data accuracy and credibility, preserving trust in the data.
- Event Anonymization: The process of eliminating or obscuring personally identifiable information (PII) and other sensitive data while preserving the integrity and structure of the data. Anonymized events can then be safely integrated into the data platform for further processing and analysis, ensuring compliance with data privacy standards and building trust with data subjects.
- Event Deduplication: Duplicate events can distort analyses and lead to inaccurate conclusions. Deduplication identifies and removes duplicate entries, ensuring data uniqueness. This process is crucial in ensuring data-driven conclusions are based on clean, non-redundant data, minimizing potential misinterpretations.
- Dead Letter Queue: Events that falter at any of the aforementioned processing stages are diverted to a dead letter queue. This specific queue facilitates subsequent examination, troubleshooting, and reprocessing, minimizing data loss. Thus, the dead letter queue serves as a safety net, ensuring that no data is lost due to processing failures, and aids in promptly diagnosing and addressing system issues.
- Writing Processed Events into the Target System: Once processed and refined, events are stored in the target system, becoming valuable data assets. Here, the transformed and enriched data becomes accessible for a variety of analytical and reporting objectives, laying the groundwork for data-driven insights.
- Dispersing Event Data in Different Storages of Serving Layer: Event data is distributed across various storage systems within the serving layer. This distribution enhances data accessibility and retrieval for diverse analytical and AI tasks, ensuring that the right data is available in the right place at the right time to support various business functions and use cases.
Collectively, these building blocks form a robust event ingestion solution that efficiently transforms raw data into high-quality data assets and subsequent actionable insights. Each component enhances the overall efficiency, accuracy, and reliability of the data processing pipeline, enabling organizations to harness the full potential of their data for strategic decision-making.
CEFI High-Level Design
CEFI employs a hybrid architecture for event ingestion and processing. Some building blocks are segregated into microservices, while others are retained as modules within a modular monolith. This strategic approach maximizes performance efficacy and operational efficiency. The hybrid model presents a range of benefits that lead to a simpler, more agile, scalable, and maintainable data processing ecosystem. In designing the event ingestion framework, we categorized the building blocks into three high-level groups, each with a distinct focus:
- Raw Event Ingress and Routing: We possess a specialized component responsible for the initial stages of raw event processing. This encompasses mirroring between data centers, simple event filtering, and routing. Acting as the gateway for incoming events, it ensures their seamless transition into the data platform. This component is designed to efficiently manage these tasks without being burdened by other processing logic. Throughout this phase, events stay intact and flow solely between distinct Kafka clusters and topics.
- Main Event Processing and Ingestion: The heart of processing logic is managed by a separate service boasting a modular structure. This setup guarantees that primary processing tasks, such as transformation, enrichment, validation, and deduplication, operate autonomously. Contrasted with the microservice strategy, this model elevates event processing performance, improves control over event processing flow, and streamlines solution scalability, thus minimizing infrastructure and administering burden. Moreover, this methodology promotes neater, easily maintainable codebases and simplifies troubleshooting.
- Event Data Dispersal: The third group of components, in charge of disseminating data from the lakehouse, leverages its own tailored architecture to efficiently distribute data to various storage systems. This targeted approach guarantees optimized event data distribution and retrieval.
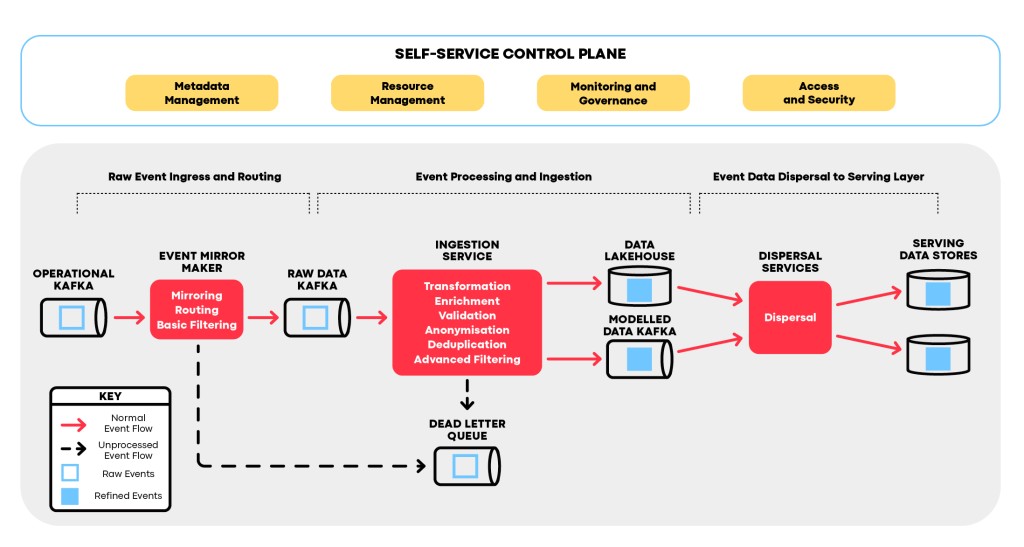
Additionally, the Control Plane, which configures, orchestrates, monitors, and safeguards CEFI, deserves mention. On a high level, it offers the following functionalities:
- Data Platform Metadata Management
- Configuration Management: Encompasses the control plane’s capability to oversee and maintain version control for configurations, scripts, and parameters used in data pipelines and workflows. This management ensures that changes are monitored, audited, and replicable, promoting consistency and reliability in data processing.
- Schema Management: Schema management involves defining and managing data asset schemas to ensure data uniformity and compatibility. The control plane oversees schema evolution, validation, and enforcement, ensuring that data conforms to predefined structures.
- Integration with Data Catalog: Integration with a data catalog involves connecting the control plane to a centralized repository of data assets, schemas, and metadata. This integration facilitates seamless data lineage, discovery, and understanding by users, enriching the overall utility of the data platform.
- Resource Management
- Resource Allocation and Optimization: The control plane orchestrates the allocation of computing resources, including CPU, memory, and storage, to various data processing tasks and workloads. Through intelligent load balancing, it guarantees efficient resource allocation, preventing resource overload and underuse. This optimization not only boots system functionality but also minimizes costs by dynamically allocating resources based on necessity while maintaining fault tolerance and robustness.
- Scaling and Auto-scaling: Both scaling and auto-scaling are integral to resource management. The control plane supports dynamic resource scaling, allowing the platform to automatically modify resource allocation based on workload demands. This capability ensures sustained performance during periods of high demand and reduced costs during low-demand periods.
- Workload Scheduling and Orchestration: Workload scheduling and orchestration involve the management of the execution of data processing tasks and procedures. The control plane ensures that tasks are systematically scheduled, sequenced, and orchestrated, taking into account dependencies and priorities.
- Governance and Monitoring
- System Monitoring and Alerting: Monitoring and alerting involve continuous monitoring of system performance, resource utilization, and data processing tasks. The control plane generates alerts and notifications when anomalies or performance issues are detected, facilitating timely responses
- Logging and Auditing: Logging and auditing features provide comprehensive records of user actions and system events. These logs are critical for compliance, troubleshooting, and thorough investigation when needed, ensuring transparency and accountability.
- Workflow Monitoring and Management: This aspect monitors the execution of data processing workflows. The control plane ensures that workflows operate reliably and effectively, granting management capabilities such as pausing, resuming, and even aborting and restarting long-running workflows.
- Access and Security
- Access Control and Authorization: Access control and authorization involve formulating and applying detailed policies that determine who can access the control panel, the data itself, and other assets. The control plane assures that only authorized users and processes can interact with the data.
- Security: The control plane enforces security protocols, such as encryption, authentication, identity management, and other industry standards, shielding data and the platform from potential security threats. It also meets compliance requirements by monitoring and enforcing security policies
Later in the blog, the self-service Control Plane will be a separate topic for discussion in the context of the entire Playtika Data Platform, not just limited to the event ingestion and processing aspect. It also touches upon crucial areas, such as error handling, failover and disaster recovery, that are relevant across the full Data Platform business domain.
In subsequent articles, we will take a deep dive into each functional block of Playtika’s event data ingestion and processing framework, offering practical advice and best practices to assist you in navigating common obstacles and enhancing your event ingestion processes. Among other topics, we will explore integration with Kafka as a source and Data Lakehouse or another Kafka as a target, event routing and filtering, data transformation and flattening events into table structures, event decoration and enrichment, deduplication, personal data processing, error management, dead lettering, and various aspects of event data quality.