Event Processing in Playtika Data Platform: Part I
By Oleg Yermilov
Introduction
Playtika’s constant portfolio expansion has led us to operate over 30 games, with thousands of gaming features that are expanded with daily releases and hundreds of thousands of events per second. In order to support the dynamic environment and nonstop growth at Playtika, we provide development platforms to studios that cover all aspects of game development and operations. These platforms help studios unleash their full potential. Our multi-petabyte decentralized data platform is a striking example of this support; it ingests and processes billions of events on a daily basis and runs thousands of ETL to prepare data for analytical, AI, or operational consumption.
In our previous article, we identified common obstacles that hinder the delivery of event data for decision-making processes. These obstacles include a lack of self-service, automation, governance, and quality in the event ingestion, transformation, and serving process.
To address these challenges we developed an event ingestion and processing framework, known as CEFI (Centralized Event Formatting and Ingestion). This framework is an integral part of our data platform and helps to unlock the analytical and operational potential of event data for Playtika’s game studios.
This blog post provides a high-level overview of CEFI and explains how it fits into the larger data platform picture. The first part of the article covers the main components of CEFI and the business use cases it serves, while the second part is a more technical deep dive.
CEFI
The primary purpose of CEFI is to process and ingest events that can be used for a variety of purposes immediately. It helps our studios ensure the quality of all types of event data during game feature development and deliver data assets without requiring special data modeling and processing skills. By data asset, we mean a valuable data structure (such as a table, Kafka topic, file, or report) that is used in business processes and data product development. These structures must be trustworthy, standardized, interoperable, observable, and secure.
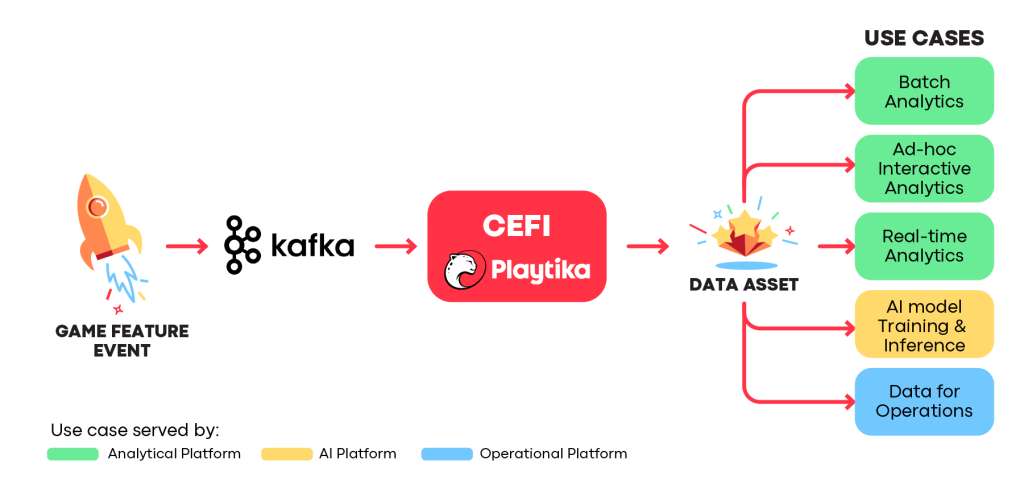
CEFI Use Cases
Every feature engineer in the product team has the ability to build data assets from raw events. For that reason, they are provided with self-service capabilities via UI console, simple APIs, and DSLs. This is what we call democratizing data asset development. This democratization is the answer to the mentioned challenges of delivering events data for decision-making but, at scale, it also requires clear standards, automated processes, and centralized governance. We will cover these topics later on, but for now, we will zoom in a bit and see what the main CEFI components are and how they fit into Playtika’s data platform.
Apache Kafka
For many years, Playtika has relied heavily on Apache Kafka as an event streaming platform. It is extremely important in gaming to have fast, scalable, secure, and durable service-to-service integration in operational and data solutions and Kafka meets this demand well.
Kafka also serves as the main entry point to our data platform. In Playtika, every event that goes through Kafka is ingested in the data platform by default and considered a first-class data citizen. This means that the event developer collects and implements data requirements with the rest of the event logic and not simply as an afterthought. This is what we call data ownership and game developers are perfect owners of the event data because they know the business logic very well and are able to implement it.
Two Paths of Event Data
Lambda architecture is a traditional Big Data approach that splits data ingestion and processing into 2 parts – Speed and Batch layers. The Batch layer populates data for a data lake or data warehouse and serves a variety of use cases that can tolerate minutes of data delay. Its use cases include data exploration, reporting, ad-hoc analytics, AI model training, and others. The Speed Layer, in turn, is responsible for delivering events for rapid processing and decision-making in a matter of seconds if not milliseconds.
The downside of the Lambda architecture is its complexity, as well as the model discrepancy between the Batch and Speed layers. This discrepancy occurs because it is difficult to achieve consistency between layers in the way data is modeled and processed among the downstream pipelines. Without consistency, it is extremely challenging to provide a robust and reliable view that combines both Batch and Speed layer data.
In CEFI we mitigate these typical Lambda architecture flaws by shifting the data modeling as far to the left as possible and providing reach functionality for the event processing and data validation while the event is still flowing in a stream.
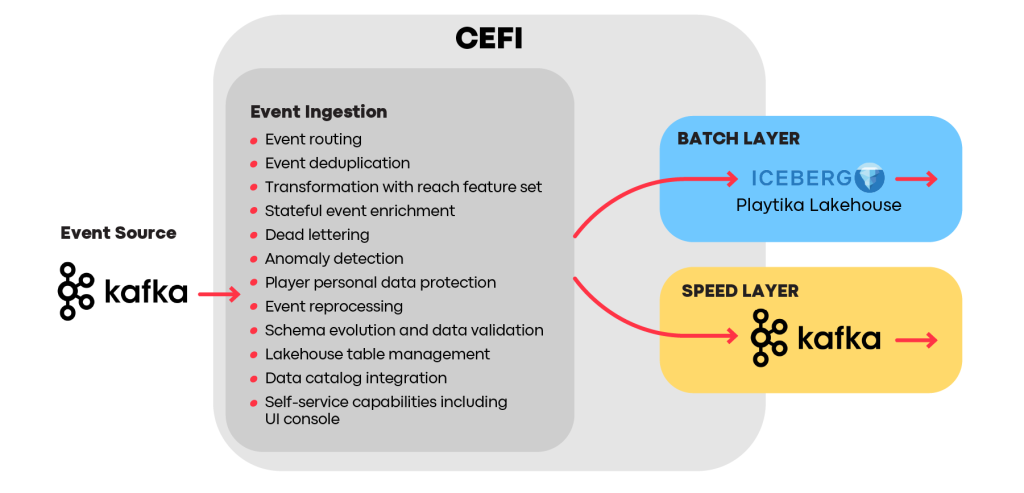
Splitting event data flow into Batch and Speed layers
As you can see in the diagram above, the Speed and Batch layers do not integrate directly with the event source. Most of the basic event operations like data cleansing, modeling, validation, enrichment, and anomaly detection are done before the event goes to the Speed and Batch layer sources, which are Apache Kafka and Apache Iceberg. Downstream, we now have various, but more unified, representations of raw event data. Analysts can easily access both real-time and historical data using familiar models, and data scientists can rely on historical data when designing AI models and data for real-time inference.
Note. The Speed/Batch layers as well as the Playtika Data Platform in general can do far more than just event processing and we will cover them in detail in future blog posts.
Event Ingestion
As we observed over the past decade, the approach of “ingest all you can, but clean and process later” does not work very well. While it might be the best strategy for some companies, we at Playtika do not split operations and data worlds into separate entities. To us, event ingestion is a defining moment in determining an event’s future and helps to unleash its analytical potential.
Every event integrated with the Playtika data platform immediately undergoes a number of validations and transformations that ensure that it becomes a high-quality data asset after its ingestion.
With ingestion, it is guaranteed that:
- Event schema complies with the expectations of the event’s consumers
- Event is transformed and ready to be published in a table format
- Personal data (which may be present in the event) is classified and protected
- Event duplicates are securely filtered out
- Event can be enriched with stateful information or dictionaries
- Event that does not comply with data quality expectations is routed to the dead-letter queue
- Event satisfies data modeling requirements and naming conventions
Additionally, we are working to identify and prevent potential bad data issues as early as possible. For example, if an event developer wants to change the existing event schema within a game and these changes do not comply with the corresponding Lakehouse model, then the event developer will be notified of this inconsistency at the event build time or with a code repository merge request. In production, if the event data for some reason doesn’t comply with the expected schema, it will be routed to the dead-letter queue for further troubleshooting and reprocessing. The event RnD owner will get an email or notification with a report of how many events were not delivered and for what reason.
Thus, there are three key points about CEFI Event Ingestion:
- After ingestion, the event becomes a high-quality data asset.
- Game feature developers are empowered to configure the event ingestion as part of their feature SDLC without engaging with data teams.
- Game feature developers become owners not only of the original event but also of its ingestion into the data platform.
After ingestion, all cleansed, transformed, and validated event data goes to the Lakehouse. In parallel, the same data can be instantly directed to the Speed layer.
Playtika Data Lakehouse
All the event data, without exception, moves to our Data Lakehouse and remains there for a time. But it is more than just persistence storage in our platform; it is the backbone for data product development in Playtika. This is the place where the real business value from events becomes available for our studios. The absolute majority of all our data pipelines use Lakehouse as a source.
In CEFI, our Lakehouse differentiates from traditional Data Lakes because the event data that is stored here has already been cleansed, standardized, and curated. This is the result of the CEFI Ingestion layer, which combines knowledge about event data provided by product teams with embedded standards, governance, and quality assurance. In Data Lake terminology, we do not have a raw (or “landing” or “bronze”) zone for events. However, Kafka can be configured to act as the event raw zone in the Data Lake when necessary.
Thanks to high-quality event data, we have no need for further data preparation steps like cleansing or standardization in many use cases. Such data serves well for AI or operational processes like Player Segmentation or Marketing Campaign Management. Quite often, after CEFI, the ingested events become fact tables in our warehouses. We call them streaming fact tables due to data freshness and the ease of moving events from stream to table format.
Batch Layer
The Batch layer in Playtika is responsible for warehousing and massive data processing to serve a plethora of use cases that require massive data processing. Traditionally, it consists of two independently scalable infrastructure elements: compute and storage. In terms of technologies, we mostly leverage Open Data Architecture with its open standards and vast community adoption.
Apache Spark covers the role of batch computing. Serving as a data processing engine, it provides convenient SQL API to build batch pipelines, among other capabilities. In our platform, we use Kubernetes as a cluster manager for Spark.
As for storage, we choose Apache Iceberg as a table format for our Lakehouse due to its reach functionality including ACID transactions, schema and partition evolution. With Iceberg, we were able to move most of the warehousing layer logic to the open table format.
In CEFI, the Batch layer is used for several use cases where event data delivers value without massive data processing. For example, aside from staying at the Lakehouse, a “personal offer” event after ingestion can be served directly to the reporting layer to bring analytical value. Thus CEFI provides capabilities for game developers to easily distribute the event to Vertica, our data source for reports and ad-hoc analytics. In that way, CEFI becomes a single umbrella solution for the studios to embed analytical power into their features in the game event design phase.
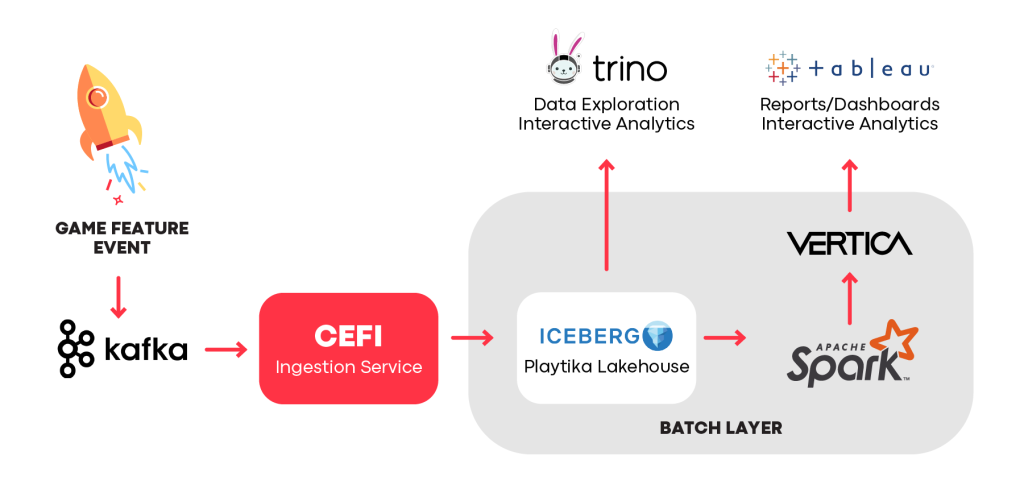
Serving event data to historical analytics use cases via the Batch Layer
Additionally, event data from the Lakehouse can be used in AI training, batch inference, or operational processes like AB Testing. We have a variety of options for how an event can be delivered via CEFI and the Batch Layer to the event data consumers. For example, Playtika’s operational platform is integrated with CEFI and provides a simple UI for game developers to define an event structure. After its definition, the event can be used in various Playtika systems including Data. Based on the event schema, all the pipelines will be automatically created and the event data will become immediately available for analytics and insights in Lakehouse and, if desired, Vertica.
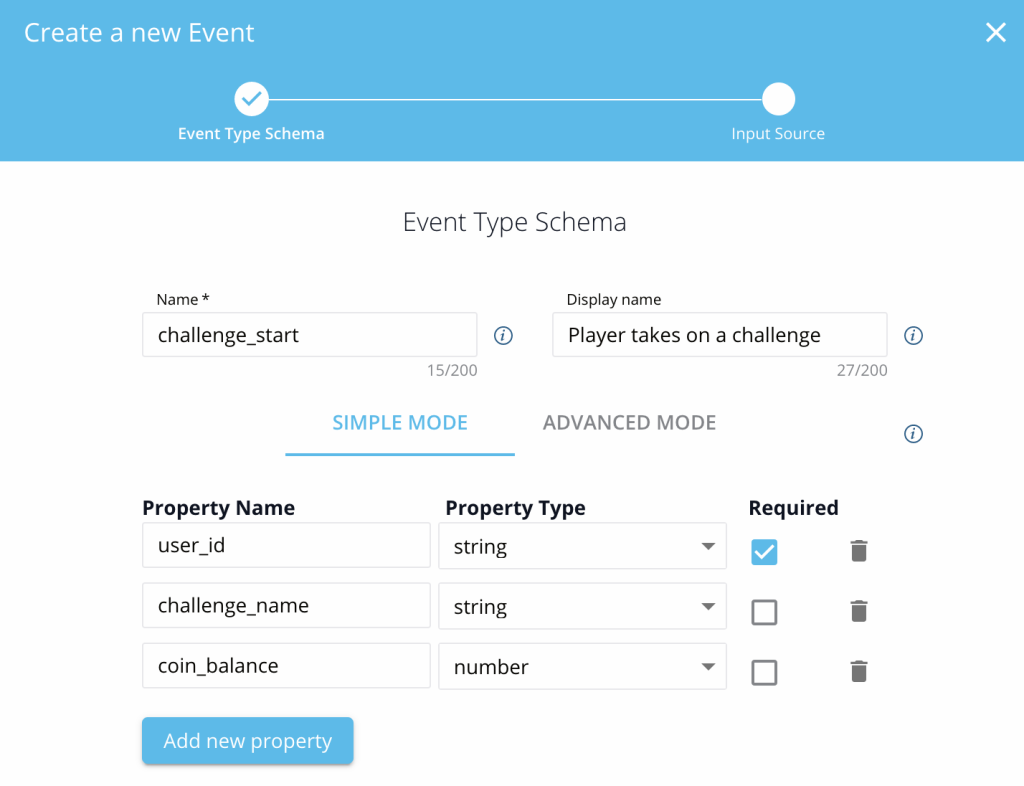
Defining event structure by a game developer
This capability simplifies event data integration, ensures a constant feedback loop from feature consumers via embedded analytics, and provides feature developers with complete control over both the event operations and the resulting data, leading to an accelerated feature SDLC.
Speed Layer
The Speed layer is helpful in cases in which we cannot tolerate minutes of data latency. It enables data freshness for feature monitoring, operational processes, and real-time use cases like online AI model inference.
The data in the Speed layer is served through Kafka and a variety of NoSQL (Time-series or Key-Value) and relational databases that can handle high workloads in a timely manner. We also leverage hybrid transactional/analytical (HTAP) databases to deliver event data to operations and operational dashboards.
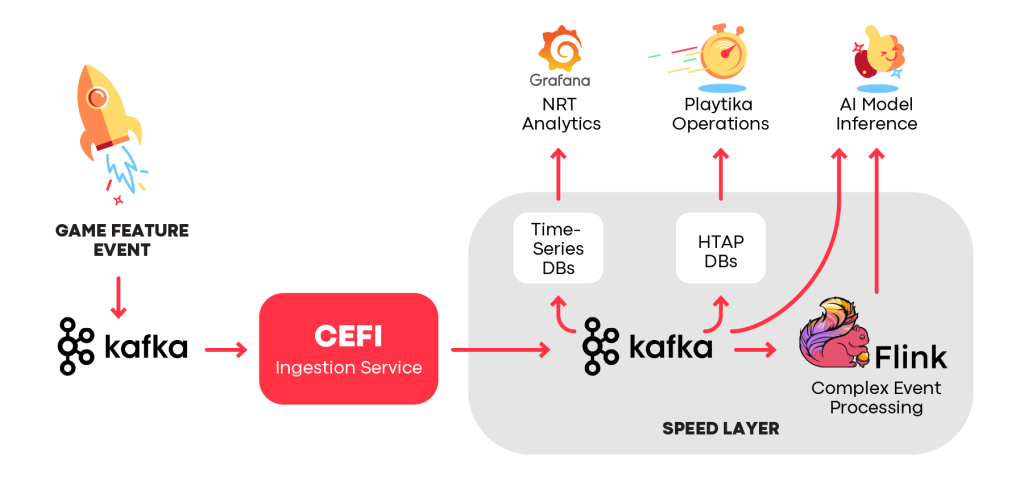
Serving event data for RT/NRT use cases
Since the event goes through the same ingestion/unification layer, we enjoy the following benefits:
- The data model presented for Speed layer use cases is mostly the same. This fact significantly improves the analytical experience and simplifies data integration for a unified representation of Batch and Speed layers.
- Events are validated during the ingestion phase, so there is strong data consistency and quality in both data processing layers.
- Personal data is already extracted, so there is no need for extra protection measures.
In the Speed layer, we use Apache Flink for scenarios in which complex event processing is required, e.g. stream analysis or data preparation for online AI model inference. Since the lion’s share of the event cleansing and transformation is done during the ingestion phase, Flink’s role is to do the rest of the modeling, including complex stateful operations, aggregations, joining, etc.
Final Thoughts
In Playtika, we use the CEFI framework as a proven method to reveal the true value behind events and enable engineering data culture. CEFI supplies high-quality data for most of the data-based processes in Playtika, like analytics, operations, and AI.
In CEFI, we encourage, empower and guide game developers to build events that meet data realities and requirements. While this is not an easy task, our development culture and organizational model allow us to bridge the operations and data worlds through proper modeling, a “schema-first” approach, SDLC integration, and automation.
In the second part of our blog dedicated to event processing, we will explore, in detail, the various capabilities of CEFI; standardization and governance, self-service capabilities, event modeling and transformation, routing, personal data protection, monitoring, metadata layer including configuration, schema management and evolution, and data catalog.